Last month, I explored how lexical analysis can detect cognitive decline, looking at the accuracy of a study from researchers M. Pattison, A. Begde, and T.D.W. Wilcockson. This study, titled ‘Detecting Dementia Using Lexical Analysis: Terry Pratchett’s Discworld Tells a More Personal Story’ explores the viability of lexical analysis as a signature of cognitive decline. I have since completed my own analysis of a sample of the work of another author to take a step towards showing whether Pratchett’s lexical decline was due to Dementia, or the refining of his craft as he grew more experienced.

Author Selection
My author of choice was Raymond E. Feist, partly because he is an author I am well acquainted with, and partly because his writing style and large, multi-book series set in one universe mirror Discworld relatively well.
I found online samples of five of his books spaced in the first 17 years of his writing career, from 1982 to 1999, spaced out so that no two books are more than 5 years apart.
The books I chose, in chronological order, were:
- Magician
- Silverthorn
- Prince of the Blood
- Shadow of a Dark Queen
- Krondor: The Assassins
Preparing the Data
In the analysis of the lexical diversity of these books, I needed to have samples of similar length, so I trimmed each of these books to just the first 50000 words in order to ensure that TTR {insert link to previous month’s post} was comparable across all the texts.
In order to properly analyse the data, I converted the first 50000 words of each text into a .txt file, and uploaded them to my system for calculating metrics.
Methodology
In order to compare even marginally to the data in the study from Pattison et al., I needed to calculate the TTR and MATTR for different token types.
This meant finding a way of differentiating between:
- Nouns
- Verbs
- Adjectives
- Adverbs
Since I don’t have the software necessary for appropriate analysis of these files, I used AI to help me write python code searching for typical suffixes of these word families.
For example:
- “ing” is often a suffix of verbs
- “ly” is often a suffix for adverbs
Once I had itemised the texts, I ran them through some more python code that calculated TTR and MATTR, which led to the following results:
Results
Using Excel for graphing, it is easier to tell visually here that over the 17 years of writing I analysed, Feist’s lexical diversity has been largely static.
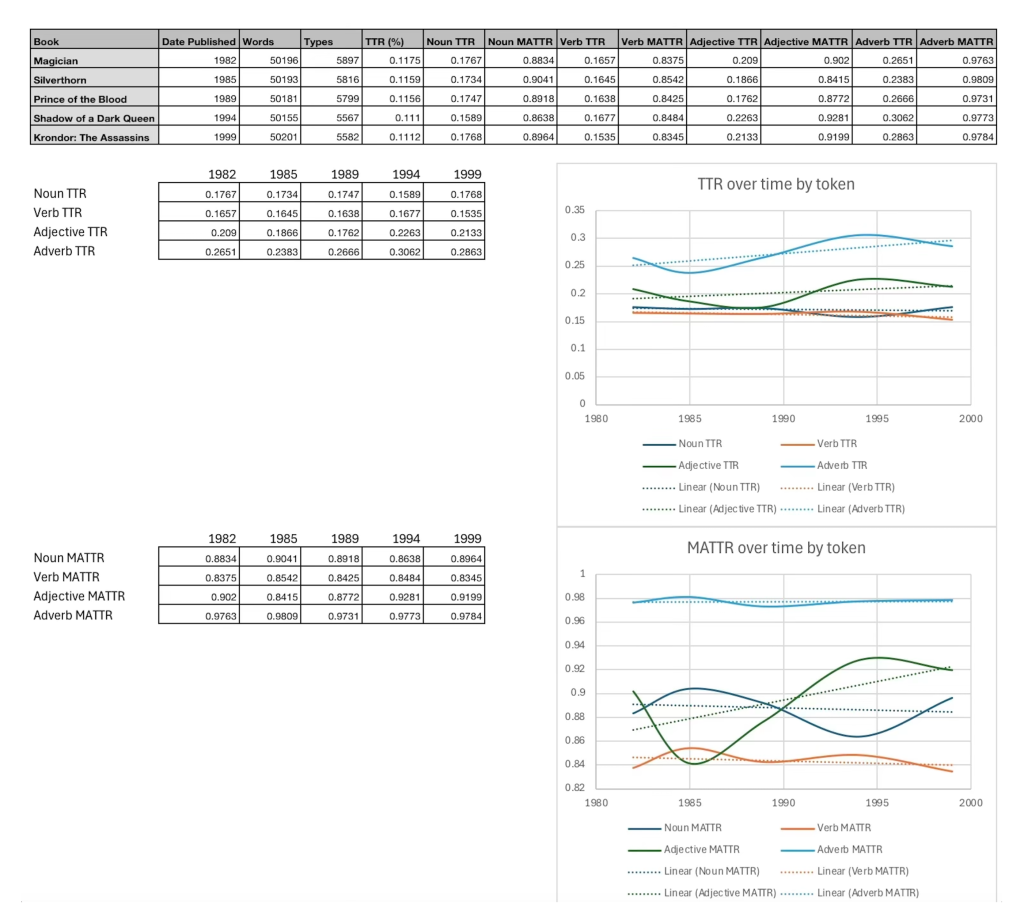
With some slight fluctuation more obvious in MATTR for adjectives and adverbs, which is unlikely to be significant due to the smaller sample sizes and rarer token types, this data can quite conclusively show that for these works at least, Feist’s lexical diversity has remained distinctly constant.
Limitations of the Approach
However, it is important to critically evaluate how comparable these results actually are to those presented in the Pattison et al. study.
Their analysis relied on a specialised corpus tool capable of:
- Accurately tagging each word by its grammatical role
- Reducing words to their base forms
This means that when they calculated, for example, noun TTR, they were counting true nouns and grouping together related forms like “run” and “running” as the same lexical item.
In contrast, my method relied on identifying likely word classes through common suffixes, which is a much cruder approach.
While patterns like:
- “-ly” for adverbs
- “-ing” for verbs
are often reliable, they are far from perfect, and inevitably introduce misclassification errors.
As a result, the absolute values of my TTR and MATTR scores are not directly comparable to those in the study.
Comparing Results
This difference becomes clear when looking at the scale of the results.
In the Pratchett study:
- Noun TTR ≈ 0.19
- Adjective TTR ≈ 0.24
- Verbs and adverbs ≈ 0.07–0.08
My Feist data, however:
- Produces much higher values for verbs and adverbs
- Produces slightly lower or similar values for nouns and adjectives
This is not necessarily a reflection of genuine stylistic difference, but rather a consequence of the less precise classification method.
In particular, the lack of proper lemmatisation, when words are reduced to their base forms, means that multiple forms of the same word often show up as artificially inflated diversity in certain categories.
Interpretation
Despite these limitations, the overall pattern observed in the Feist data remains meaningful.
While the Pratchett study identifies a clear and statistically significant decline in lexical diversity, particularly in nouns and adjectives, over time, no such trend is visible in Feist’s work.
Instead:
- His lexical diversity remains broadly stable across all five texts
- Only minor fluctuations are present
- There is no consistent upward or downward trajectory
This distinction is crucial.
Even if the exact numerical values differ, the presence or absence of a directional trend is far less sensitive to methodological imperfections than the precise magnitude of the scores.
Conclusion
Therefore, while my analysis cannot replicate the precision of the original study, it still provides useful comparative insight.
The stability of Feist’s lexical diversity over nearly two decades suggests that the kind of sustained decline observed in Pratchett’s later works is not simply a universal feature of long-term writing development.
Instead, it supports the interpretation proposed by Pattison et al., that significant and sustained reductions in lexical diversity, particularly within specific word classes, may reflect underlying cognitive changes rather than normal stylistic evolution.